Pagina 2 di 11
PresentazioneLa Gainward Bliss GeForce GTX 280, è la decima generazione di architettura per la famiglia di prodotti NVIDIA. Attualmente rappresenta nella propria gamma di prodotti di fascia alta, la più veloce soluzione video a singola scheda. Questo chip è costruito con tecnologia produttiva a 65 nanometri nella fonderia taiwanese TSMC. Il chip GT200 in totale integrata ben 1,4 miliardi di transistor, per una superficie complessiva del die estremamente elevata, quantificata in circa 650 millimetri quadrati.


Purtroppo il processo produttivo a 65 nanometri non ha aiutato Nvidia a diminuire le dimensioni del die,creando non pochi problemi.

Impressionante la grandezza del die della GTX 280 messa a confronto con il processore Intel Penryn.
Con la GPU GT200 NVIDIA ha preso spunto dall'architettura utilizzata nelle soluzioni G80 e G92, introducendo significative innovazioni ma mantenendo invariato il design di base. Troviamo 240 stream processors (SP) nella scheda GeForce GTX 280, raggruppati a gruppi di 8 ciascuno in quelli che vengono indicati con il nome di “streaming multiprocessors (SM)”. Un gruppo di 3 “streaming multiprocessore” viene indicato con il nome di “thread processing cluster o TPC”: abbiamo quindi in totale 10 TPC e 30 SM per ogni scheda video GeForce GTX 280.


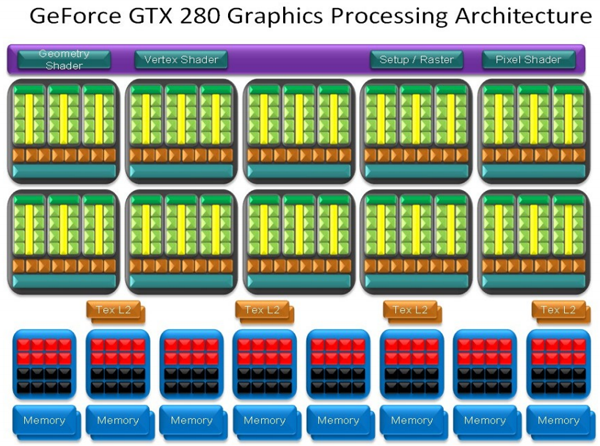
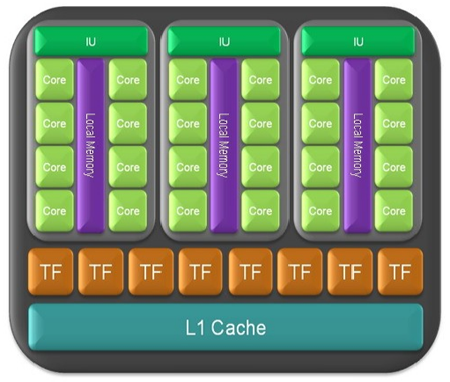
Negli schemi “sopra riportati” riguardanti l'architettura del GT200, possiamo immediatamente capire come NVIDIA abbia suddiviso internamente le varie unità di elaborazione. Nella parte superiore della GPU trova posto la logica che gestisce la suddivisione dei vari thread all'interno dei core, accanto alle unità per il setup e la rasterizzazione.
I 10 blocchi identici sono i TPC, all'interno dei quali sono chiaramente visibili le 3 SM, ciascuna dotata di 8 SP. Per ogni SM sono associate una unità di elaborazione full precision, indicata in colore verde nella parte superiore dell'SM, e due texture units distinguibili dal colore marrone. Ogni stream processor è capace di eseguire operazioni sia con interi che in virgola mobile, accedere alla memoria ed eseguire operazioni di logica. L'architettura è con pipeline multiple, in grado di eseguire una istruzione per ogni thread per ogni ciclo di clock.
Il file di registro locale interno ad ogni SM è stato raddoppiato rispetto a quello implementato nelle precedenti GPU G80 e G92; questo permette alla GPU GT200 di elaborare un numero maggiore di shader, o shader di più elevata complessità, senza necessità di eseguire swap verso la memoria con un conseguente impatto negativo sulle prestazioni.
Diverse ottimizzazioni, sono state apportate da parte di Nvidia all’interno alle special function unit interne agli SM, così da ottenere maggiore efficienza nell'utilizzo delle istruzioni in virgola mobile MUL. In particolare ogni stream processor può elaborare quasi a piena velocità due operazioni di tipo MAD (Multiply-Add) e una di tipo MUL, utilizzando l'unità MAD integrata nello stream processor per eseguire un MUL e un ADD per ogni ciclo di clock, accanto all'unità SFU che esegue una seconda operazione MUL. Pertanto risulta che ogni stream processor ha una potenza di elaborazione massima pari a 933 Gigaflops in elaborazioni in virgola mobile single precision.
Abbiamo detto che all'interno di ogni SM sia presente una unità di calcolo double precision. Nvidia ha infatti implementato nelle GPU GT200 anche questa funzionalità, particolarmente importante soprattutto quando la GPU viene utilizzata per elaborazioni di GPU Computing, ovvero per calcoli paralleli tipicamente delegati alla cpu, grazie alla nuova tecnologia “CUDA”, che vedremo ed analizzeremo in seguito.
Considerando che ogni 8 stream processor è presente una unità di calcolo double precision, la potenza elaborativa massima effettivamente ottenibile in double precision con una GPU GT200 è circa pari a 90 Gigaflops.
Nel GT200 troviamo un bilanciamento tra la capacità di indirizzare le textures e di filtrarle. Le unità implementate permettono infatti di indirizzare 80 textures in totale per ogni ciclo di clock, oppure di filtrare 80 pixel bilinerar o 40 pixel filtrati 2:1 anisotropic. Architettura simile anche per le ROPs, che sono state incrementate fino a 32. Troviamo il supporto a AA supersampled, multisampled, transparency adaptive e coverage sampling, oltre al blending di frame buffer di render target surfaces in virgola mobile, sia FP16 che FP32. Le ROPs possono operare con un output massimo di 32 pixel per clock, ottenuto con l'elaborazione di 4 pixel per ciclo di clock per ciascuna delle 8 partizioni; nello schema di funzionamento della GPU GT200 si notano le 8 partizioni nella parte inferiore, ciascuna collegata direttamente a due coppie di chip memoria con un bus a 64bit. 32 ROPs vogliono dire 32 pixel per clock in output e 32 pixel per clock in blend: le nuove unità, infatti, possono eseguire blend a velocità doppia .
Uno dei principali limiti delle precedenti soluzioni Nvidia erano da ricercarsi nelle prestazioni con geometry shader:. NVIDIA è intervenuta in GT200 per migliorare sensibilmente questo elemento architetturale, portando ad un incremento di 6 volte dei buffer di output interni alla GPU. Infatti sono presenti varie ottimizzazioni minori all'interno della GPU; il protocollo di comunicazione è stato migliorato così da incrementare l'efficienza nelle trasmissioni tra il driver e il front end.
La Gainward Bliss GeForce GTX 280 ha frequenza di clock è pari a 602 MHz. Nel GTX 280 troviamo l'utilizzo di 16 moduli memoria, ciascuno con un bus da 32bit di ampiezza per un totale di 512bit; la risultante è una bandwidth massima pari a ben 141,7 Gbytes al secondo, grazie all'utilizzo di moduli memoria GDDR3 da 2.214 MHz di clock.
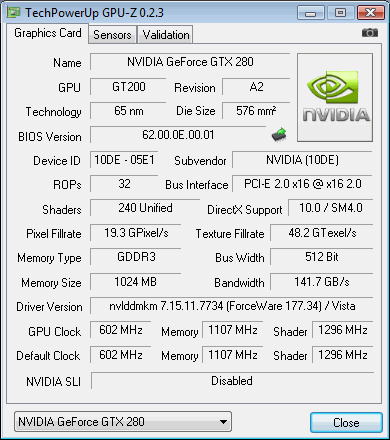
Si noti, come il programma GPU-Z riconosca in maniera esatta, tutte le caratteristiche della GPU.
I chip memoria sono disposti su entrambi i lati del PCB della scheda video. Come è di consuetudine, il PCB delle ultime schede video Nvidia sono di colore nero.


La soluzione GeForce GTX 280 integra 1 Gbyte di memoria video di tipo DDR3. Questo valore dovrebbero permettere di sfruttare al meglio risoluzioni video molto elevate “oltre i 1920x1200” , in abbinamento ai giochi particolarmente esigenti in termini di dotazione massima di memoria, evitando che i frames al secondo vengano fortemente penalizzati.